When starting with Apache Kafka, you’re overwhelmed with a lot of new concepts: topics, partitions, groups, replicas, etc. Although Kafka documentation does a great job in explaining all of these concepts, sometimes it’s good to see them in practical scenarios. That’s what this post will try to achieve, by pointing a few findings/scenarios and solutions/explanations/links for each of them.
First of all, a few basic concepts in short, you can find complete explanation on Kafka documentation. These concepts will be used in more depth when we discuss the scenarios.
- Broker: It’s a running instance of Kafka server. You can have a lot of them running at the same time in different servers/data centers.
- Topic: The place where your messages are added in/consumed from.
- Partition: If you want to scale out your topic to improve your throughput (both in and out) you can divide it into different partitions and spread them among different brokers. Kafka is very efficient on this and you’ll get pretty much linear scalability. By default, each topic has 1 single partition.
- Group: This is a concept related to consumers and by using it you can get point-to-point semantics (only one subscriber will get each message) and publish-subscriber (all subscribers get all messages).
- Replicas: By default, each topic partition is stored in just one single broker. This is not a very reliable configuration if you want HA, so you can configure partitions to have multiple replicas, i.e., to be stored in different brokers.
- Partition Leader: Each partition has one single leader that is responsible for receiving and dispatching messages. If a partition leader dies, one of the brokers that contains replicas of that partition will take over and continue to serve requests.
This is just a short description of these concepts so we can start looking into some scenarios. If you want (and should) check more details, please refer to Kafka documentation.
Preparing the environment
You can try each one of the scenarios yourself if you want to. You just need to have Docker and Docker compose installed.
Clone the git repo https://github.com/wurstmeister/kafka-docker.git to get hold of the project containing some of the files we need. Create a file named “docker-compose-kafkatest.yml” with the following content.
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
build: .
ports:
- "9092"
environment:
KAFKA_BROKER_ID: "1"
KAFKA_ADVERTISED_HOST_NAME: <your ip address>
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
This docker compose file will create 2 containers, one for zookeeper and one for kafka. Create two more files with the following content:
config_group1.config
group.id=group1
config_group2.config
group.id=group2
These files will be needed to allows us to set the group id of our consumers. Before each scenario, run the commands:
docker-compose --project-name test -f docker-compose-kafkatest.yml up docker cp config_group1.config test_kafka_1:/tmp docker cp config_group2.config test_kafka_1:/tmp
“test_kafka_1″ is the name given by docker-compose: “test” is the name of the project, “kafka” the name of the container and “1″ the number of the instance related to this container.
And after each scenario, run:
docker-compose --project-name test -f docker-compose-kafkatest.yml down
This will ensure we get a fresh environment for each one of the scenarios, like running test cases. You will need to use multiple terminals to run all the scenarios/commands.
Scenarios
Here’s a list of a few scenarios that you might come across while working with Kafka. This is not by any means an exhaustive list.
Scenarios from the consumer’s point of view
Scenario 1
What happens if I have a topic with 1 partition and 2 consumers within the same group?
Just one of the consumers gets the messages, like in a queue, while the other one is completely idle. If one consumer is shut down, the other one assumes and it starts to receive the messages. You should always strive to divide your topic into more partitions than the number of consumers, even if you start with just one consumer and one broker. By having multiple partitions it’s easier to add more consumers to share the load. From the documentation: “Typically, there are many more partitions than brokers and the leaders are evenly distributed among brokers”.
# 1 - Creates a topic docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test-topic # 2 - Starts 2 consumers using the same group id docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group1.config docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group1.config # 3 - Starts the producer. To send a message, just type any text and press Enter. docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic
If you check both consumers’ terminal, you can see that just one of them is receiving all messages. If you kill it and send another message, it’ll be delivered to the other consumer that is still running.
Scenario 2
What happens if I have a topic with 1 partition and 2 consumers with different groups?
This is like a publish-subscribe model, all consumers will get all messages.
# 1 - Creates a topic docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test-topic # 2 - Starts 2 consumers using different group ids docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group1.config docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group2.config # 3 - Starts the producer. docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic
If you check the consumers’ terminal, you can see that both are receiving the same messages.
Scenario 3
How are messages split among the partitions of a topic?
If you don’t specify a key in the message to be used to partition the data, messages will be automatically assigned to partitions by Kafka using round-robin algorithm.
Scenario 4
I have a topic with 10 partitions and 1 consumer and I want to add more consumers to share the load.
When you have just 1 consumer, it’ll be getting messages from all 10 partitions. Whenever a new consumer is added, the partitions will be balanced among the consumers automatically, i.e., each one will get 5 partitions. And so on as more consumers are added.
# 1 - Creates a topic divided into 10 partitions docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 10 --topic test-topic # 2 - Starts a consumer docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group1.config # 3 - Starts a producer and send a message docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic # 4 - Checks the consumer of each partition. You can see all partitions are being consumed by just one consumer docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-consumer-groups.sh --zookeeper zookeeper:2181 --describe --group group1 # 5 - Starts 2 more consumers for same group docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group1.config docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test-topic --consumer.config /tmp/config_group1.config # 6 - You can see now that the partitions are evenly distributed among the 3 consumers docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-consumer-groups.sh --zookeeper zookeeper:2181 --describe --group group1
It’s nice to see how Kafka dynamically shares the load as more consumers are added to the group. See that this is only possible because the topic is split into enough partitions, otherwise you’d end up with idle consumers, like in Scenario 1.
Scenario 5
I have two applications, A and B, and I want each application to get only one copy of each message published in a given topic.
Like scenario 2, use different group ids for each application. If you need multiple consumers for each application, each message will be delivered only once for each application.
It’s important to notice that there’s just one broker acting as leader for each partition in any given time, so all the scenarios above hold regardless of the number of brokers in your cluster.
Scenarios from the broker’s point of view
Scenario 1
I want to describe a given topic, i.e., to know who is the leader of each partition, who contains replicas and which replicas are in sync.
# 1 - Starts a second broker docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=2 --name=test_kafka_2 -p 9092 -d kafka # 2- Starts a third broker docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=3 --name=test_kafka_3 -p 9092 -d kafka # 3 - Creates a topic with replication factor 3 split among 10 partitions docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 3 --partitions 10 --topic test-topic # 4 - Lists how partitions are balanced across the 3 brokers of the cluster docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic
The output of 4) is similar to:
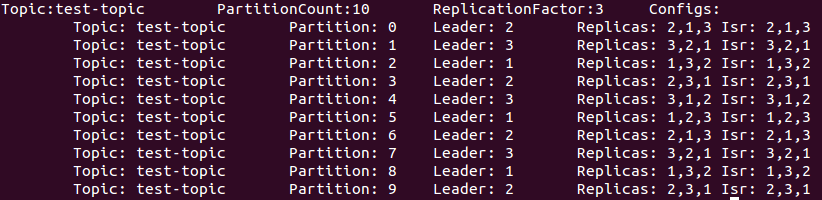
For each partition, you can see:
- Which broker is acting as its leader
- In which brokes it’s being replicated to
- Which brokers are “in-sync” replicas (ISR).
Scenario 2
I want to know which consumers are getting each partition…etc.
This is like scenario 4 from previous section:
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-consumer-groups.sh --zookeeper zookeeper:2181 --describe --group group1
Scenario 3
I want to resize my cluster by adding/removing brokers and I want that existing partitions/leadership are re-balanced among them.
As we saw on scenario 1, it’s very easy to add new brokers to a Kafka cluster. However, the existing partitions are not automatically rebalanced (regardless of whether you’re adding/removing a broker), so a few steps need to be executed manually.
# 1 - Starts a second broker
docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=2 --name=test_kafka_2 -p 9092 -d kafka
# 2 - Creates a topic with replication factor 2 split among 10 partitions
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 2 --partitions 10 --topic test-topic
# 3 - Describes the topic, so we can see partitions are evenly distributed among brokers 1 and 2
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic
# 4 - Starts a third broker
docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=3 --name=test_kafka_3 -p 9092 -d kafka
# 5 - Describes the topic and we can see that no partitions were assigned/replicated to broker 3
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic
# 6 - Creates a JSON file with the name of the topic we want to re-distribute and copies it to the container
echo '{"topics": [{"topic": "test-topic"}],"version":1}' > topics-to-rebalance.json
docker cp topics-to-rebalance.json test_kafka_1:/tmp
# 7 - Generates a plan of how the topic will be redistributed. Nothing happens at this point, it’s just the proposed reassignment.
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-reassign-partitions.sh --zookeeper zookeeper:2181 --topics-to-move /tmp/topics-to-rebalance.json --broker-list "1,2,3" --generate
# 8 - Copies the output of the “Proposed partition reassignment configuration" section to the file “execute-topics-rebalance.json" (it can have any name) and copies it to the container
docker cp execute-topics-rebalance.json test_kafka_1:/tmp
# 9 - Executes the partition reassignment
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-reassign-partitions.sh --zookeeper zookeeper:2181 --reassignment-json-file /tmp/execute-topics-rebalance.json --execute
# 10 - Verify the reassignment happened successfully
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-reassign-partitions.sh --zookeeper zookeeper:2181 --reassignment-json-file /tmp/execute-topics-rebalance.json --verify
# 11 - Rebalance partitions leadership (http://kafka.apache.org/documentation.html#basic_ops_leader_balancing)
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-preferred-replica-election.sh --zookeeper zookeeper:2181
# 12 - Describer the topic again. We can see that the partitions are now evenly distributed among brokers 1, 2 and 3
docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic
As you can see, this is not a very trivial task. If you knew exactly how you wanted to spread the partitions within the cluster, you could have created the reassignment JSON file yourself. Another point to note is regarding partition election. If you run the describe command after step 10, you’ll see that although the partitions are replicated among all brokers, only brokers 1 and 2 are leaders, so we need to run a tool to rebalance leadership. You can see more details here.
Scenario 4
I have a topic with X replicas (regardless of the number of partitions) and these replicas are located on brokers 1, 2 and 3. One of the nodes (broker 1) crashed and it won’t be able to recover, what should I do?
Just replace that node with a new one and assign the same broker id to it. The data related to the partitions which are replicated to it will be automatically fetched from the leader. However, it won’t take back the leadership of its partitions automatically. Instead, you need to “Rebalance partitions leadership” manually, as done on scenario 3.
# 1 - Starts a second broker docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=2 --name=test_kafka_2 -p 9092 -d kafka # 2 - Starts a third broker docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=3 --name=test_kafka_3 -p 9092 -d kafka # 3 - Creates a topic with replication factor 2 split among 10 partitions docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 2 --partitions 10 --topic test-topic # 4 - Describes the topic. You can see partitions are evenly balanced among brokers 1, 2 and 3 docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic # 5 - Kills broker 2 docker kill test_kafka_2 && docker rm test_kafka_2 # 6 - Describes the topic. You can see that partitions’ leadership were split between brokers 1 and 2 and that ISR doesn’t contain broker 2 anymore. docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic # 7 - Starts a new broker with broker id = “2", like the one that was brought down previously docker-compose --project-name test -f docker-compose-kafkatest.yml run -e KAFKA_BROKER_ID=2 --name=test_kafka_2 -p 9092 -d kafka # 8 - Describes the topic. You can see that ISR looks good again now, although leadership is still unbalanced docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic # 9 - Rebalance partitions’ leadership docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-preferred-replica-election.sh --zookeeper zookeeper:2181 # 10 - Now everything is evenly distributed again docker exec -it test_kafka_1 /opt/kafka_2.11-0.10.0.0/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic test-topic
Scenario 5
One of the brokers (say broker 1) is restarted.
This is similar to scenario 4 in the sense it’ll cause the existing brokers to take over the leadership of broker 1’s partitions. When broker 1 is brought back, its partitions are automatically replicated to it and you need to run “Rebalance partitions leadership” to complete the process.
Summary
This is by no means a post about Kafka internals/details, but only a few scenarios/findings that you might run into while playing with it. Sometimes it’s easier to see real scenarios and how to fix them instead of just read the documentation.
